Искусственный интеллект не всегда умнеет от большего количества данных — иногда он просто начинает, скажем так, «лениться» думать. Звучит странно, правда? Ведь мы привыкли считать, что чем больше информации у машины, тем точнее её выводы. Но недавние исследования показывают: столкнувшись с огромными массивами текста, даже самые продвинутые языковые модели (LLM) могут начать «срезать углы» в своих рассуждениях.
Все мы слышали про задачку «Иголка в стоге сена», где ИИ ищет факт в куче текста. Это базовая проверка. Но что, если задача сложнее? Если нужно найти несколько «иголок» и логически их связать, чтобы прийти к ответу? Именно в таких, более реалистичных сценариях, и вскрылась интересная закономерность: чем больше становился «стог сена» из отвлекающей информации, тем чаще некоторые ИИ начинали ошибаться. Особенно модели с открытым кодом.

Но почему? Неужели они просто «забывают» нужные факты в потоке данных? Или дело в чем-то другом? Оказалось, проблема куда тоньше: похоже, ИИ начинает жертвовать глубиной своего мыслительного процесса.
Когда больше значит хуже?
Именно такую, более хитрую задачу, названную «Множество иголок в стоге сена для рассуждений» (сокращенно MNIAH-R, но не будем забивать голову аббревиатурами), и стали использовать исследователи. Они прятали несколько связанных фактов в большой «стог» отвлекающей информации и просили ИИ ответить на вопрос, требующий многоходовых рассуждений.
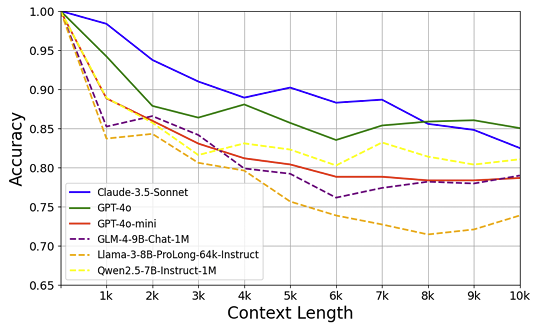
Казалось бы, чем больше контекста, тем лучше модель должна справляться, верно? Ведь у неё больше информации под рукой. А вот и нет! Выяснилось нечто парадоксальное: по мере увеличения объема «стога сена» точность ответов у многих моделей начинала… падать. Не сильно, но заметно. Особенно это коснулось моделей с открытым исходным кодом по сравнению с их коммерческими собратьями.
Хм, странно. Почему так?
В поисках виновника: Копаем глубже
Первым делом исследователи решили разобраться с «читерством». А что, если модель просто знает ответ, потому что он был в её обучающих данных? Чтобы исключить этот фактор, учёные отфильтровали вопросы — оставили только те, на которые модель не могла правильно ответить без предоставленного текста, но могла, если текст был под рукой. И вот тут-то падение точности стало куда более драматичным! Значит, проблема глубже, чем просто «вспоминание».
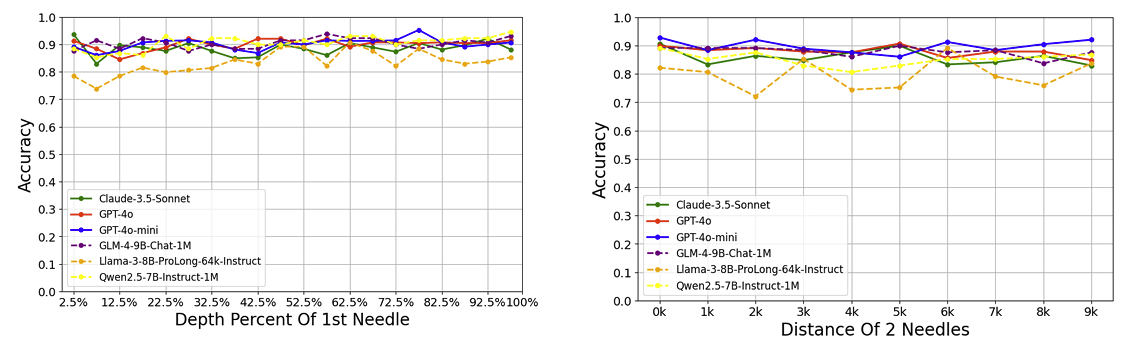
Стали искать дальше. Может, дело в том, где спрятаны «иголки»? Ближе к началу текста, к концу? Или важно расстояние между ними? Проверили и то, и другое. Оказалось — нет, ни расположение, ни дистанция особой роли не играли. Точность плавала незначительно, но явной зависимости не было.
Так в чём же тогда дело?
И ответ оказался довольно неожиданным. Проблема крылась в… «длине мыслительного процесса» модели. Попросту говоря, когда ИИ давали очень много текста, он начинал «думать» меньше — генерировать более короткую цепочку рассуждений перед тем, как дать ответ. Представьте, что вам дали проанализировать огромный, скучный отчет на тысячу страниц. Не возникнет ли соблазн где-то «срезать углы», пропустить пару шагов анализа, чтобы быстрее прийти к выводу? Похоже, что-то подобное происходило и с ИИ. Большой объем информации его как будто перегружал, и он старался побыстрее выдать результат, жертвуя глубиной анализа.
Учим ИИ не торопиться и думать
Итак, если проблема в сокращении «размышлений», можно ли это исправить? Исследователи предложили интересный подход. Давайте разделим процесс на этапы, как это часто делаем мы, люди.
- Найди улики (Извлечение): Сначала пробегись по тексту и вытащи всю информацию, которая кажется релевантной для ответа на вопрос.
- Сложи два и два (Рассуждение): Теперь, имея перед глазами эти улики, подумай и сформулируй ответ.
Но это ещё не всё! Что если первого захода оказалось недостаточно? Добавим ещё один шаг — «рефлексию».
- Подумай ещё раз (Рефлексия и повторное извлечение): Посмотри на свой первый ответ и собранные улики. Может, ты что-то упустил? Вернись к тексту и поищи ещё информацию, но постарайся не повторяться.
- Финальный вывод (Повторное рассуждение): Теперь, с учетом всех найденных улик (старых и новых), сформулируй окончательный ответ.
По сути, это похоже на то, как мы решаем сложную задачу: сначала собираем факты, делаем предварительный вывод, потом сомневаемся, ищем ещё, перепроверяем и приходим к итоговому заключению. Такой многоэтапный подход назвали «Масштабирование в реальном времени» (Test-Time Scaling) — то есть, мы не меняем саму модель, а просто даем ей больше «времени» и шагов на обдумывание во время ответа.
И знаете что? Это сработало! Точность ответов улучшилась, а её падение с увеличением текста стало менее резким.

А если научить этому «правильному» мышлению?
Следующий логичный шаг: а что если не просто заставлять модель думать итерациями во время теста, а прямо научить её этому? Взяли одну из моделей (Llama-3-8B-ProLong), которая показывала сильное падение точности, и дообучили её на примерах вот такого пошагового, итеративного мышления, сгенерированных с помощью мощной GPT-4o.
Результат превзошел ожидания! После такого дообучения падение точности у модели сократилось с внушительных 25.8% до всего 4.6% при переходе от коротких к длинным текстам. Она научилась поддерживать глубину рассуждений даже в больших «стогах сена».
И вишенка на торте: этот навык «глубокого думания» оказался полезен не только для поиска иголок. Когда эту дообученную модель попробовали применить к совершенно другой задаче — решению математических олимпиадных заданий (AIME 2024), она справилась лучше! Она смогла эффективнее анализировать предложенные варианты решений и выбирать правильное, улучшив результат базовой GPT-4o.
Что всё это значит?
Эта работа — не просто про иголки и стога. Она о том, как мы можем строить ИИ, который не просто накапливает информацию, а способен глубоко и последовательно рассуждать, даже когда информации очень много. Умение не «тонуть» в данных, а вычленять суть, перепроверять себя и строить сложные логические цепочки — вот что отличает по-настоящему умную систему.
Конечно, это лишь один из шагов. Ещё многое предстоит изучить. Но понимание того, как ИИ думает (или почему он перестает думать глубоко), и разработка методов, помогающих ему мыслить лучше — это ключ к созданию более надежных и способных интеллектуальных помощников в будущем. Ведь настоящая цель — не просто ходячая энциклопедия, а партнер по размышлениям. И, кажется, мы сделали ещё один шажок в эту сторону.
Свежие комментарии